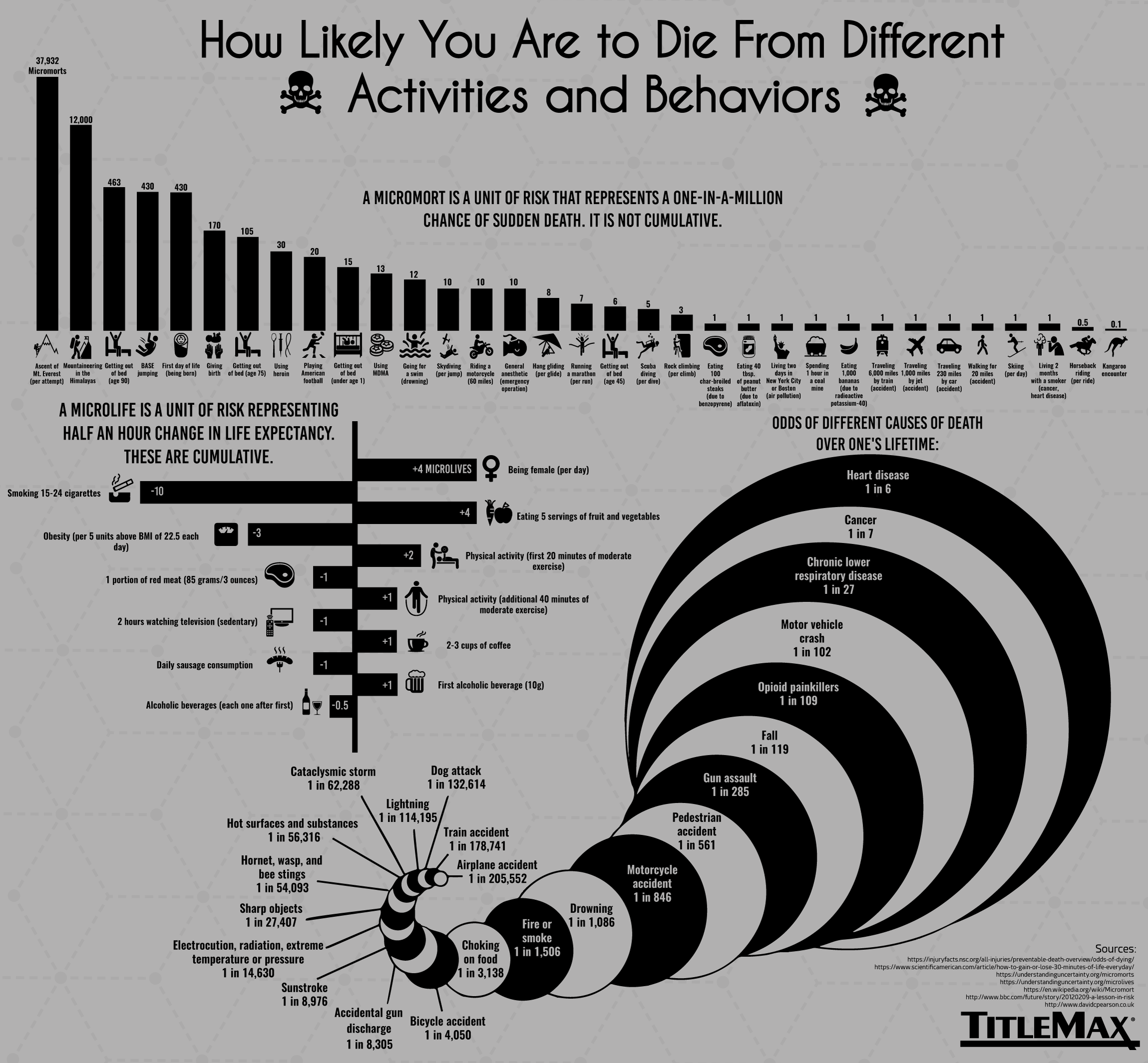
A micromort, or \(\mu M\), is a unit of risk defined as a 1 in a million chance of death.
I don’t think I’m a morbid person, but I find the unit fascinating. In general, it’s probably fair to say that human fears are way out of proportion with actual risks. For example, a common source of fear is traveling on an airplane. Yet if you calculate the expected micromort exposure, you find that air travel is at just about a hundred times safer per mile compared to traveling by car. Concretely, a flight from JFK to LAX works out to \(0.2 \mu M\), which is the equivalent of 27 miles by car; by comparison, the average American drives 37 miles every day.
So you’d have to fly to LA and back every day to surpass the risk that average Americans take every day driving, in terms of micromorts.
The example suggests that micromorts could be a promising way to quantify everyday risks, and to calibrate our collective fears accordingly. (I’m not sure the unit packs a very intuitive punch – it’s like reporting sugar in grams, rather than teaspoons to obscure the exact amount. However, we are generally exposed to such small levels of “risk of death” on a daily basis that it’s hard to come up with a more intuitive proposal. Quantifying it at all seems like a step in a positive direction.)
This is also relevant to Covid-19. With global confirmed deaths surpassing 500,000 in late June, and with excess deaths causing 5 to 7 times normal mortality at peak times in the worst affected areas, we are on average experiencing much higher micromort exposures than usual. I’m the kind of person who is very risk averse (I’ve been accused of being overly cautious and of turning into an agoraphobic, lol). But I think it’s a good time to consider the question: exactly how much risk do I routinely experience from Coronavirus and from all other factors?
Disclaimers
-
I am not a medical expert.
-
I don’t think Micromorts should be used as advice for how seriously to take Covid-19.
The problem is that these calculations do not include the micromorts passed on to others due to the spread of the virus. This micromort spread is what really gives us all an obligation to be careful (wear a mask, don’t gather in large crowds, and avoid contact especially indoors) and is not accounted for in the following numbers. Assuming exponential spread, the number of micromorts you are responsible for will also grow exponentially, far greater than just the risk to your own life. This should be a sobering thought, particularly because you could be infectious at any time, and just not know it.
-
The word micromort suggests a fixed quantity of risk, but in most of these calculations it is actually only an estimate based on average risk experienced by people in similar situations. For example, the plane travel vs. car travel example uses average deaths per person-mile as a proxy for risk, which is arguably not a perfect model, as perhaps risk of crash on an airplane is not linearly correlated with miles traveled (e.g., it could be linearly correlated with number of flights taken instead).
-
Finally, to put micromort exposures in context, the time frame matters. For my personal analysis, I will be using a time frame of one year so that all of the different amounts can be compared meaningfully.
Analysis from the New York Times
With those disclaimers out of the way, I like this overall analysis from the New York Times. An individual in NYC had experienced (at that time) roughly an additional \(50 \mu M\) per day because of Covid-19. Living in Michigan, it was instead \(11 \mu M\) per day. By comparison, if you contract coronavirus, it’s up to \(10000 \mu M\) (across all ages).
This corresponds to an infection fatality rate of 1%; the true number is probably somewhere between 0.5 and 0.9, higher in places with a large number of cases (see 1, 2, 3, 4, 5).
Note that the rate is at least an order of magnitude more for older people, and at least an order of magnitude less for younger people;
it has been estimated at about \(100\) to \(300 \mu M\) for ages 20-29 or \(60000 \mu M\) for ages 65+
(1, 2).
My Personal Analysis
Here’s what I’ve calculated for my own personal breakdown of micromort exposure, from various sources. I didn’t try to make sure all the numbers are perfectly accurate (it seems to be quite hard for most factors), but only roughly reasonable, hopefully in the right order of magnitude.
Minor Sources: travel and outdoor activities
-
Car travel: \(1.2 \mu M\) per year (200 miles). I travel by car very infrequently.
-
Plane travel: \(2.1 \mu M\) per year (30000 miles). It will be somewhat less this year.
-
Walking around the city: \(5 \mu M\) per year (250 miles).
-
Skiing: \(2 \mu M\) per year (2 days spent skiing).
Sources for the numbers were Vox and TitleMax.
Major Non-Covid Sources
Next I wanted to know the major factors that contribute to my chances of death in general (pre-Covid). First, we need a good baseline. According to ssa.gov and echoed by Statista for recent years, Americans age 25-29 die at about the rate of \(1600 \mu M\) per year for men, and \(600 \mu M\) for women. The increase for men is largely due to greater number of accidental and injury-related deaths.
Overall, that means an average American of my age experiences about \(\boldsymbol{1100 \mu M}\) per year.
(Note that this baseline is not a good estimate of my personal risk, but it serves as a natural reference point.)
Whatever accounts for the bulk of these micromorts, then, we expect will completely dwarf the “minor sources” I listed above. So what are the sources? This chart gives us a rough idea of the major causes for ages 25-44: unintentional injuries (33%), cardiovascular diseases (CVD) (12%, including both heart disease and stroke), cancer (11%), and homicide (6%), roughly in that order, followed by a bunch of other diseases like diabetes, HIV, and influenza.
Statista
gives a more specific ranking for the age range of 25-29: accidents (45%), suicides (14%), homicide (11%), cancer (4.6%), and CVD (4.5%).
For this post, I’m ignoring everything except these top 5. The most important question that comes to mind is, what lies in the mysterious “accidents” category?
The answer is primarily: (1) car accidents, and (2) drug overdoses, particularly from the Opioid crisis in the United states since the 1990s (which has worsened during the pandemic).
For example Injury facts lists poisoning as accounting for \(287 \mu M\) and motor vehicle accidents for \(117 \mu M\) at age 25, with all other preventable injury-related deaths at a lower order of magnitude.
Fortunately for me, neither of these factors are significant in my own life; we have already seen that traveling by car is only a minor contributor for me, even less than walking. We can additionally exclude suicide. I will also set aside homicide, because I am in a low-risk, privileged demographic (I haven’t looked into this in detail, but for example, homicides are concentrated in high-poverty areas).
That leaves cardiovascular disease and cancer: those ominous diseases that basically account for the bulk of unpreventable deaths (or at least, only-partially-preventable deaths) that occur in people of all ages (though much more frequently with age).
I found this difficult to get a good personalized number on.
The issue is that while many calculators exist for risk of stroke, heart attack, and cancer (e.g. 1, 2, 3), for example based on blood pressure, height and weight, exercise, diet, etc., they are often optimized for older people, and seem to perform poorly (vastly overestimating risk) for younger people. In the end, I just did a generic calculation based on number of overall deaths for people of age 25-35, using two journal articles (1, 2). We get \(98 \mu M\) for both CVD and cancer, but it’s probably fair (if completely arbitrary) to cut CVD in half due to that I am generally healthy (not overweight or high blood pressure). So my rough estimate is:
A related factor and indirect cause of death not included in the discussion so far is air pollution. The TitleMax source identifies air pollution as a major risk factor, saying that it accounts for \(0.5 \mu M\) per day if you live in NYC or Boston, i.e \(180 \mu M\) per year.
But the resulting deaths are due to the same factors as above: “increased mortality from stroke, heart disease, chronic obstructive pulmonary disease, lung cancer and acute respiratory infections” according to WHO. Thus, adding in \(180 \mu M\) a year for living in Philadelphia would probably not be correct; the above numbers were based on averages for all Americans, which already takes a good deal of air pollution into account. To avoid overcounting, I will thus not include a specific number on this.
It’s worth mentioning two other major person-specific sources that fall into the normal (non-Covid) category. The first is traveling by motorbike, if you do that regularly, which is far more dangerous than traveling by car. The second is giving birth, which is about \(200 \mu M\) in the United States, according to the NYT source (and TitleMax’s estimate is similar).
Covid-19 Sources
We have already established that contracting the virus for a person of my age range is about \(100\) to \(300 \mu M\), i.e., comparable or higher than my exposure to most of the major non-Covid sources over the next year. The question is, though, what is my personal risk of getting it in the next year? And what is my personal risk of death accounting for comorbidities? These are more difficult to be precise about. I tried different things:
-
According to this calculator based on various basic information, environmental, behavioral, and health factors, my risk of infection is about 5% and my risk of death if infected is .05% (\(500 \mu M\)), which puts my micromort exposure at \(25 \mu M\). According to the details of their methodology, the risk of infection appears to be estimated over a long enough time frame for the pandemic to completely play out (say, at least 12-18 months), and also assumes no vaccine. As a result, the 5% number is likely an overestimate. Some issues are that the app isn’t designed by medical professionals, and it doesn’t take into account my location.
-
A second calculator based on health and behavioral factors puts my personal risk of catching the virus through community transmission at 0.009% per week. Using 850 cases in Philadelphia in the last week, assuming an underreporting factor of 5, there are approximately 4300 new cases this week, which is a .2% chance of infection for the average person (assuming everyone is equally likely, which ignores people who are already immune). So apparently my behaviors make me much safer than I would be otherwise. If we take a .01% risk which accumulates over the next \(50\) weeks, we get a .5% risk (note that the approximation of multiplying by 50 instead of using \(1 - (1-p)^{50}\) is accurate for a probability this small).
Overall, by different calculations I have somewhere between a .5% and 5% risk of contracting the virus in the next year assuming my current risk-averse behaviors; and I experience somewhere between \(100\) and \(500 \mu M\) if I get the virus. Going with 3% and \(400 \mu M\) to approximate these numbers erring towards the high end, we have:
- Covid-19 in the next year (in Philadelphia, by different calculations, assuming risk-averse behavioral factors, age 25, and lack of comorbidities): \(\sim 12 \mu M\).
The full range is \(.5\) to \(25 \mu M\).
However, this is assuming I continue to be very careful; if I stop being careful and encounter more people on a daily basis (right now I just encounter one person), it will increase substantially.
Conclusions
I have two main conclusions from this exercise. First, as a very risk-averse person, Covid-19 is the highest source of micromorts for me other than CVD and cancer.
The raw number of micromorts that I calculated in the end was not as high as I expected, and not as high as some of my estimates in earlier drafts.
However, if my behaviors change to be less careful about contracting the virus, my personal risk will likely increase substantially, and would be on par with the highest factors or greater.
As a thought experiment, suppose that more risky behaviors would result in an order of magnitude increase. Then that would be \(120 \mu M\), or \(120 - 12 = 108 \mu M\) from Covid-19 that are preventable. This would probably be much higher than what I can prevent otherwise, say, by getting better exercise.
Thus, my second conclusion is more speculative: Covid-19 is likely the largest source of preventable micromorts for me in the next year. It would be nice to do a detailed analysis of this in a future post.
Thanks to Kei Nishimura-Gasparian, Ariana Spentzos, and Joseph Stanford for providing feedback on earlier drafts of this post.

{kind=link}